REST API
Kein Web Scraping
Bitte verwenden Sie für automatisierte Zugriffe ausschließlich die REST API. Das Scraping der Weboberfläche wird nicht unterstützt und kann zu unerwarteten Fehlern führen. Die API bietet alle notwendigen Endpunkte für eine programmatische Integration.
Die Librario REST API ermöglicht Ihnen die programmatische Integration und Automatisierung Ihrer Bibliotheksprozesse. Sie können damit alle wichtigen Funktionen von Librario in Ihre bestehende IT-Infrastruktur bzw. in Ihre Prozesse einbinden.
Zugriff auf die API
Die API ist unter folgender URL erreichbar:
https://<ihre-firma>.mylibrar.io/api, zum Beispiel: https://app.mylibrar.io/api
Falls Sie eine eigene Subdomain zugewiesen bekommen haben, können Sie diese in der URL verwenden.
API-Dokumentation
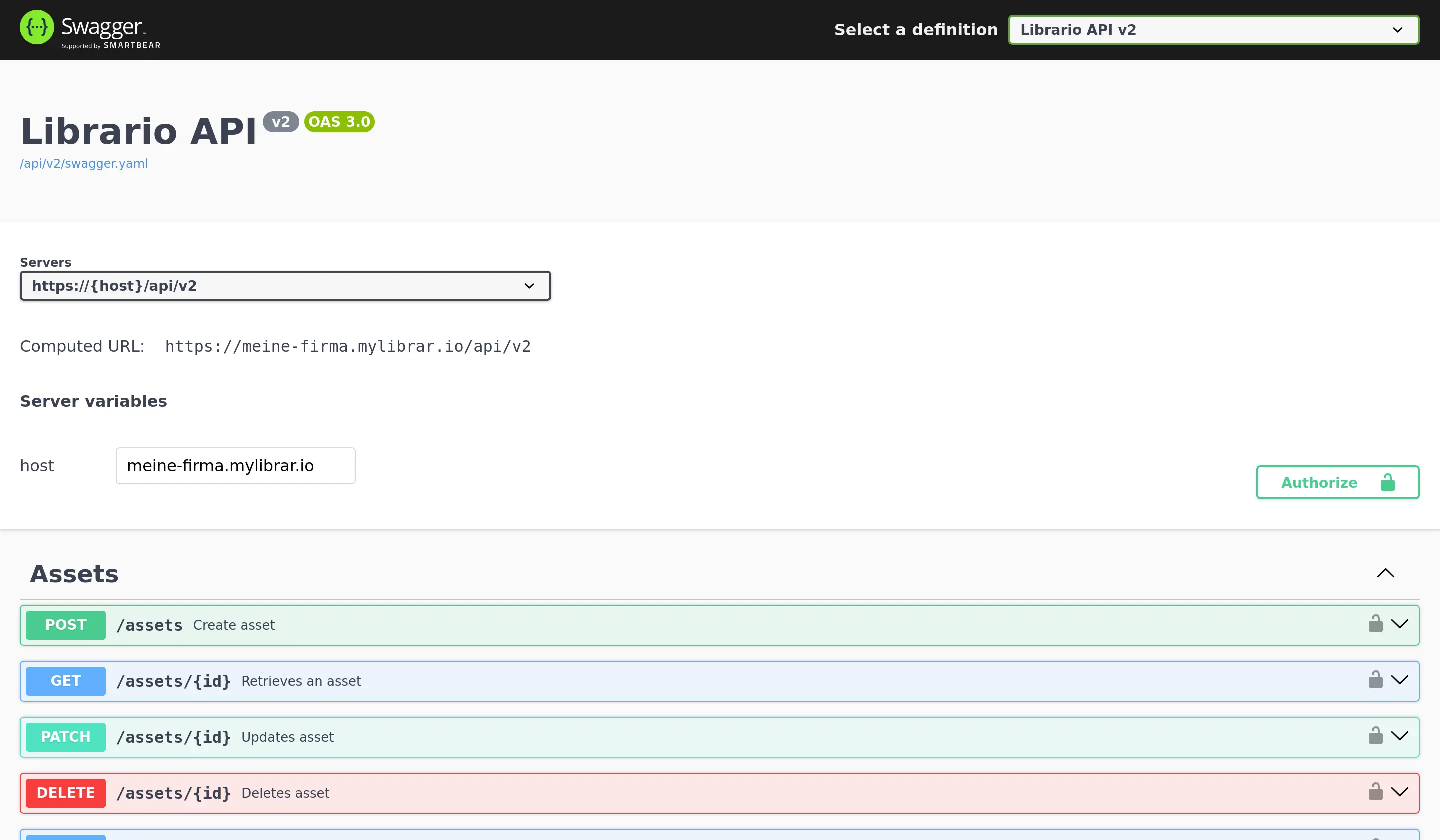
Die vollständige API-Dokumentation steht Ihnen in zwei Formaten zur Verfügung:
-
Swagger UI: Eine interaktive Web-Oberfläche zum Erkunden der API
- Erreichbar unter
https://<ihre-firma>.mylibrar.io/api - Ermöglicht das direkte Testen von API-Aufrufen
- Zeigt Beispielanfragen und -antworten
- Bietet Download der OpenAPI-Spezifikation als
swagger.yaml
- Erreichbar unter
-
OpenAPI-Spezifikation (
swagger.yaml): Eine maschinenlesbare Beschreibung der API- Basis für die automatische Generierung von API-Clients
- Kann in API-Entwicklungswerkzeuge importiert werden
- Hilfreich für die Verwendung mit KI-Tools wie ChatGPT oder Claude
Authentifizierung
Die API verwendet Basic Authentication für den Zugriff. Alle Personen können sich mit ihren normalen Librario-Zugangsdaten an der API anmelden. Die Berechtigungen entsprechen dabei den in der Anwendung konfigurierten Rollen.
Technische Benutzer für Integrationen
Es wird empfohlen, für automatisierte Prozesse dedizierte technische Zugänge anzulegen. Dies macht die Integration unabhängig von personenbezogenen Accounts und vereinfacht die Verwaltung von Zugriffsrechten.
Datenformat
Die API nutzt das JSON-Format für den Datenaustausch. Dieses Format ist in allen gängigen Programmiersprachen einfach zu verarbeiten.
Paginierung
Bei Listen-Endpoints wird die Ausgabe auf 25 Einträge pro Seite begrenzt. Um alle Datensätze zu erhalten, müssen Sie die Seiten nacheinander abrufen.
Die Navigation wird durch spezielle Response-Header erleichtert:
X-Total: Gesamtanzahl der verfügbaren EinträgeLink: URLs für erste/vorherige/nächste/letzte Seite
Der Link Header macht die Implementierung besonders einfach:
Solange ein next Link vorhanden ist, gibt es weitere Seiten abzurufen.
Typische Anwendungsfälle
Die folgenden Beispiele zeigen die API-Nutzung mit zwei verschiedenen Ansätzen:
curlals einfaches Kommandozeilen-Tool für schnelle Tests und Debugging- Ruby mit der eingebauten Net::HTTP Bibliothek für Produktiv-Implementierungen
Benutzer:innen-Management
In vielen Organisationen soll der Lebenszyklus von Benutzerkonten automatisiert werden, etwa wenn neue Mitarbeitende eingestellt werden oder das Unternehmen verlassen.
curl
# Neue:n Benutzer:in anlegen
curl -X POST "https://ihre-firma.mylibrar.io/api/v2/users" \
-u "tech_user@example.com:password" \
-H "Content-Type: application/json" \
-d '{
"email": "max.mustermann@example.com",
"name": "Max Mustermann",
"roles": ["librarian"]
}'
# Rollen zuweisen
curl -X PATCH "https://ihre-firma.mylibrar.io/api/v2/users/123/roles" \
-u "tech_user@example.com:password" \
-H "Content-Type: application/json" \
-d '{"roles": ["admin", "librarian"]}'
# Benutzer:in löschen
curl -X DELETE "https://ihre-firma.mylibrar.io/api/v2/users/123" \
-u "tech_user@example.com:password"
Ruby
require 'net/http'
require 'json'
require 'uri'
class LibrarioClient
def initialize(host:, username:, password:)
@host = host
@username = username
@password = password
end
def create_user(email:, name:, roles: [])
# Neue:n Benutzer:in anlegen
post('/users', {
email: email,
name: name,
roles: roles
})
end
def assign_roles(user_id:, roles:)
# Rollen zuweisen/aktualisieren
patch("/users/#{user_id}/roles", {
roles: roles
})
end
def delete_user(user_id:)
# Benutzer:in löschen bei Austritt
delete("/users/#{user_id}")
end
private
def request(method, path, data = nil)
uri = URI("https://#{@host}/api/v2#{path}")
request = case method
when :get then Net::HTTP::Get.new(uri)
when :post then Net::HTTP::Post.new(uri)
when :patch then Net::HTTP::Patch.new(uri)
when :delete then Net::HTTP::Delete.new(uri)
end
request.basic_auth(@username, @password)
request['Content-Type'] = 'application/json'
request.body = data.to_json if data
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
JSON.parse(response.body) unless response.body.empty?
end
def post(path, data) ; request(:post, path, data) ; end
def patch(path, data) ; request(:patch, path, data) ; end
def delete(path) ; request(:delete, path) ; end
end
# Verwendung:
client = LibrarioClient.new(
host: 'ihre-firma.mylibrar.io',
username: 'tech_user@example.com',
password: 'password'
)
client.create_user(
email: "max.mustermann@example.com",
name: "Max Mustermann",
roles: ["librarian"]
)
Datenimport
Beim Umstieg auf Librario müssen oft Daten aus dem Altsystem migriert werden. Die API ermöglicht einen strukturierten Import von Publikationen mit zugehörigen Dateien.
Einfache Publikation erstellen
Der einfachste Fall ist das Erstellen einer Publikation ohne angehängte Dateien:
curl
curl -X POST "https://ihre-firma.mylibrar.io/api/v2/publications" \
-u "tech_user@example.com:password" \
-H "Content-Type: application/json" \
-d '{
"title": "Beispiel-Publikation",
"authors": [
{"name": "Max Mustermann", "type": "person"}
],
"publishable_type": "Book",
"isbn": "978-3-86680-192-9"
}'
Ruby
# frozen_string_literal: true
require 'net/http'
require 'json'
require 'uri'
# Einfacher Import einer Publikation ohne Dateien
uri = URI('https://ihre-firma.mylibrar.io/api/v2/publications')
request = Net::HTTP::Post.new(uri)
request.basic_auth('tech_user@example.com', 'password')
request['Content-Type'] = 'application/json'
request.body = {
title: 'Beispiel-Publikation',
authors: [
{ name: 'Max Mustermann', type: 'person' }
],
publishable_type: 'Book',
isbn: '978-3-86680-192-9'
}.to_json
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
if response.is_a?(Net::HTTPSuccess)
publication = JSON.parse(response.body)
puts "Publikation erstellt mit ID: #{publication['id']}"
else
puts "Fehler: #{response.body}"
end
Import mit Dateien
Für den Import von Publikationen mit angehängten Dateien (z.B. PDFs) ist ein mehrstufiger Prozess erforderlich:
Workflow-Übersicht
sequenceDiagram
participant Client
participant API
participant S3
Client->>API: 1. POST /publications
(Publikation erstellen)
API-->>Client: publication_id
Client->>API: 2. GET /assets/presign
(Presigned URL anfordern)
API-->>Client: presign_response mit
URL & Formularfeldern
Client->>S3: 3. POST Multipart-Upload
(Datei hochladen)
S3-->>Client: Success (204)
Note over Client: File ID extrahieren:
Alles nach "cache/"
Client->>API: 4. POST /assets
(Asset mit file.id erstellen)
API-->>Client: asset_id
Wichtiger Hinweis zur File ID
Die file.id für die Asset-Erstellung entspricht dem S3-Pfad ohne das cache/ Präfix.
Beispiel:
S3 Key: cache/1/a078705e6e55b512bb2b596c12a2a12b/dokument.pdf
File ID: 1/a078705e6e55b512bb2b596c12a2a12b/dokument.pdf
Das Backend sucht die Datei unter cache/{file.id} in S3. Bei falscher ID erhält man den Fehler:
file "..." not found on storage (Aws::S3::Errors::NoSuchKey)
curl
#!/bin/bash
# Publikation erstellen
PUBLICATION=$(curl -X POST "https://ihre-firma.mylibrar.io/api/v2/publications" \
-u "tech_user@example.com:password" \
-H "Content-Type: application/json" \
-d '{
"title": "Technische Dokumentation",
"publishable_type": "Report",
"published_on": "2024-01-15"
}')
PUBLICATION_ID=$(echo "$PUBLICATION" | grep -o '"id":[0-9]*' | cut -d: -f2)
# Presigned URL für Upload anfordern
PRESIGN=$(curl -X GET "https://ihre-firma.mylibrar.io/api/v2/assets/presign?filename=dokument.pdf&type=application/pdf" \
-u "tech_user@example.com:password")
# Wichtige Felder extrahieren
UPLOAD_URL=$(echo "$PRESIGN" | jq -r '.url')
KEY=$(echo "$PRESIGN" | jq -r '.fields.key')
FILE_ID=${KEY#cache/} # Entfernt "cache/" Präfix
# Content-Disposition aus Policy extrahieren (für S3-Validierung)
POLICY=$(echo "$PRESIGN" | jq -r '.fields.policy')
CD_VALUE=$(echo "$POLICY" | base64 -d | jq -r '.conditions[] | select(has("Content-Disposition")) | .["Content-Disposition"]')
# Datei zu S3 hochladen (--form-string für korrekte Escape-Behandlung)
curl -X POST "$UPLOAD_URL" \
--form-string "key=$KEY" \
--form-string "Content-Disposition=$CD_VALUE" \
--form-string "Content-Type=application/pdf" \
--form-string "policy=$POLICY" \
--form-string "x-amz-credential=$(echo "$PRESIGN" | jq -r '.fields["x-amz-credential"]')" \
--form-string "x-amz-algorithm=$(echo "$PRESIGN" | jq -r '.fields["x-amz-algorithm"]')" \
--form-string "x-amz-date=$(echo "$PRESIGN" | jq -r '.fields["x-amz-date"]')" \
--form-string "x-amz-signature=$(echo "$PRESIGN" | jq -r '.fields["x-amz-signature"]')" \
--form "file=@dokument.pdf"
# Asset erstellen und mit Publikation verknüpfen
curl -X POST "https://ihre-firma.mylibrar.io/api/v2/assets" \
-u "tech_user@example.com:password" \
-H "Content-Type: application/json" \
-d "{
\"publication_id\": $PUBLICATION_ID,
\"name\": \"Technische Dokumentation\",
\"content_type\": \"application/pdf\",
\"file\": {
\"id\": \"$FILE_ID\",
\"storage\": \"cache\",
\"metadata\": {
\"size\": $(stat -f%z dokument.pdf),
\"filename\": \"dokument.pdf\",
\"mime_type\": \"application/pdf\"
}
}
}"
Ruby
# frozen_string_literal: true
require 'net/http'
require 'json'
require 'uri'
require 'base64'
require 'mime/types'
class LibrarioImport
def initialize(host:, username:, password:)
@host = host
@username = username
@password = password
end
def import_publication(data)
uri = URI("https://#{@host}/api/v2/publications")
request = Net::HTTP::Post.new(uri)
request.basic_auth(@username, @password)
request['Content-Type'] = 'application/json'
request.body = data.to_json
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
if response.is_a?(Net::HTTPSuccess)
publication = JSON.parse(response.body)
puts "✓ Importiert: #{data[:title]} (ID: #{publication['id']})"
publication
else
puts "✗ Fehler bei #{data[:title]}: #{response.body}"
nil
end
end
def attach_file(publication_id:, file_path:, name: nil)
unless File.exist?(file_path)
puts "✗ Datei nicht gefunden: #{file_path}"
return nil
end
mime_type = MIME::Types.type_for(file_path).first&.content_type || 'application/octet-stream'
file_name = File.basename(file_path)
display_name = name || file_name
presign_data = get_presigned_url(filename: file_name, type: mime_type)
return nil unless presign_data
file_id = upload_to_s3(presign_data, file_path)
return nil unless file_id
create_asset(
publication_id: publication_id,
file_id: file_id,
file_path: file_path,
name: display_name,
mime_type: mime_type
)
end
private
def get_presigned_url(filename:, type:)
uri = URI("https://#{@host}/api/v2/assets/presign")
uri.query = URI.encode_www_form(filename: filename, type: type)
request = Net::HTTP::Get.new(uri)
request.basic_auth(@username, @password)
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
if response.is_a?(Net::HTTPSuccess)
JSON.parse(response.body)
else
puts "✗ Fehler beim Anfordern der Upload-URL: #{response.body}"
nil
end
end
def upload_to_s3(presign_data, file_path)
uri = URI(presign_data['url'])
fields = presign_data['fields']
# KRITISCH: File ID = S3 Key ohne "cache/" Präfix
file_id = fields['key'].sub(%r{^cache/}, '')
policy = JSON.parse(Base64.decode64(fields['policy']))
cd_value = policy['conditions'].find do |c|
c.is_a?(Hash) && c['Content-Disposition']
end&.dig('Content-Disposition')
boundary = "----RubyFormBoundary#{Time.now.to_i}"
body = build_multipart_body(fields, file_path, cd_value, boundary)
request = Net::HTTP::Post.new(uri)
request['Content-Type'] = "multipart/form-data; boundary=#{boundary}"
request.body = body
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
if response.is_a?(Net::HTTPSuccess)
file_id
else
puts "✗ Fehler beim Hochladen zu S3: #{response.code} #{response.body}"
nil
end
end
def build_multipart_body(fields, file_path, cd_override, boundary)
parts = []
fields.each do |key, value|
value = cd_override if key == 'Content-Disposition' && cd_override
parts << "--#{boundary}"
parts << "Content-Disposition: form-data; name=\"#{key}\""
parts << ''
parts << value
end
parts << "--#{boundary}"
parts << "Content-Disposition: form-data; name=\"file\"; filename=\"#{File.basename(file_path)}\""
parts << "Content-Type: #{fields['Content-Type'] || 'application/octet-stream'}"
parts << ''
parts << File.binread(file_path)
parts << "--#{boundary}--"
# WICHTIG: \r\n als Zeilentrenner (HTTP-Standard)
parts.join("\r\n")
end
def create_asset(publication_id:, file_id:, file_path:, name:, mime_type:)
uri = URI("https://#{@host}/api/v2/assets")
request = Net::HTTP::Post.new(uri)
request.basic_auth(@username, @password)
request['Content-Type'] = 'application/json'
request.body = {
publication_id: publication_id,
name: name,
content_type: mime_type,
file: {
id: file_id,
storage: 'cache',
metadata: {
size: File.size(file_path),
filename: File.basename(file_path),
mime_type: mime_type
}
}
}.to_json
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
if response.is_a?(Net::HTTPSuccess)
asset = JSON.parse(response.body)
puts "✓ Datei '#{name}' erfolgreich angehängt (ID: #{asset['id']})"
asset
else
puts "✗ Fehler beim Anhängen der Datei '#{name}': #{response.body}"
nil
end
end
end
# Verwendung:
importer = LibrarioImport.new(
host: 'ihre-firma.mylibrar.io',
username: 'tech_user@example.com',
password: 'ihr_passwort'
)
publication = importer.import_publication({
title: 'Technische Dokumentation 2024',
publishable_type: 'Report',
published_on: '2024-01-15',
authors: [
{ name: 'Dr. Maria Schmidt', type: 'person' },
{ name: 'Forschungsinstitut GmbH', type: 'corporate' }
],
categories: %w[Technik Forschungsbericht]
})
if publication
importer.attach_file(
publication_id: publication['id'],
file_path: 'dokument.pdf',
name: 'Hauptdokument'
)
end
Häufige Fehlerquellen
- Policy-Validierung: Die Content-Disposition muss exakt dem Wert in der S3-Policy entsprechen
- File ID Format: Verwenden Sie
file_id = key.sub(/^cache\//, '')statt komplexerer Extraktion - Multipart-Encoding: Zeilenumbrüche müssen
\r\nsein, nicht nur\n
Automatischer Abgleich von Publikationslisten
Ein häufiges Szenario ist der Abgleich von EndNote-Exporten mit dem Librario-Bestand. Dabei soll ermittelt werden, welche Publikationen bereits verfügbar sind und welche noch beschafft werden müssen.
curl
# Einzelne DOI prüfen
curl -G "https://ihre-firma.mylibrar.io/api/v2/publications" \
-u "tech_user@example.com:password" \
--data-urlencode "doi=10.1234/example.doi"
Ruby
Voraussetzungen für die Input-Datei
- CSV-Datei mit UTF-8 Kodierung
- Enthält eine Spalte mit dem Header “DOI”
- Weitere Spalten werden in die Ausgabedatei übernommen
Beispiel endnote_export.csv:
DOI,Title,Authors,Year
10.1234/example.1,Example Paper 1,John Doe,2023
10.1234/example.2,Example Paper 2,Jane Smith,2022
Format der Ausgabedatei
Die Ausgabedatei availability_report.csv enthält alle Spalten der Eingabedatei plus zwei zusätzliche Spalten:
Status: “Verfügbar” oder “Nicht verfügbar”URL: Link zur Publikation in Librario (falls verfügbar)
Beispiel availability_report.csv:
DOI,Title,Authors,Year,Status,URL
10.1234/example.1,Example Paper 1,John Doe,2023,Verfügbar,https://firma.mylibrar.io/publications/123
10.1234/example.2,Example Paper 2,Jane Smith,2022,Nicht verfügbar,
require 'net/http'
require 'json'
require 'uri'
require 'csv'
class PublicationChecker
def initialize(host:, username:, password:)
@host = host
@username = username
@password = password
end
def check_publications(input_file:, output_file:)
rows = CSV.read(input_file, headers: true)
rows.each do |row|
next unless row['DOI']
uri = URI("https://#{@host}/api/v2/publications")
uri.query = URI.encode_www_form(doi: row['DOI'])
request = Net::HTTP::Get.new(uri)
request.basic_auth(@username, @password)
response = Net::HTTP.start(uri.hostname, uri.port, use_ssl: true) do |http|
http.request(request)
end
data = JSON.parse(response.body)
if response.is_a?(Net::HTTPSuccess) && !data['records'].empty?
pub = data['records'].first
row['Status'] = 'Verfügbar'
row['URL'] = "https://#{@host}/publications/#{pub['id']}"
else
row['Status'] = 'Nicht verfügbar'
row['URL'] = ''
end
end
CSV.open(output_file, 'w') do |csv|
csv << rows.headers
rows.each { |row| csv << row }
end
end
end
# Verwendung
checker = PublicationChecker.new(
host: 'ihre-firma.mylibrar.io',
username: 'tech_user@example.com',
password: 'password'
)
checker.check_publications(
input_file: 'endnote_export.csv',
output_file: 'availability_report.csv'
)
Backups und Datensicherung
Die API bietet umfassende Möglichkeiten zur Datensicherung.
Ein einfaches Backup mittels /publications/all Endpunkt ermöglicht das seitenweise Abrufen aller Publikationen.
Weitere Details finden Sie in der Backup-Dokumentation.
Best Practices
Rate Limiting
Um die API-Server nicht zu überlasten, beachten Sie bitte:
- Maximale Anfragerate: 60 Anfragen pro Minute
- Bei Listenabfragen: Paginierung verwenden
- Große Datenmengen in kleineren Batches verarbeiten
Fehlerbehandlung
Die API verwendet folgende HTTP-Statuscodes:
200: Anfrage erfolgreich401: Nicht autorisiert403: Zugriff verweigert404: Ressource nicht gefunden429: Zu viele Anfragen (Rate Limit überschritten)500: Interner Serverfehler
Fehlerantworten enthalten zusätzliche Details im JSON-Format:
{
"error": {
"code": "RecordNotFound",
"message": "Requested record not found"
}
}